- tags
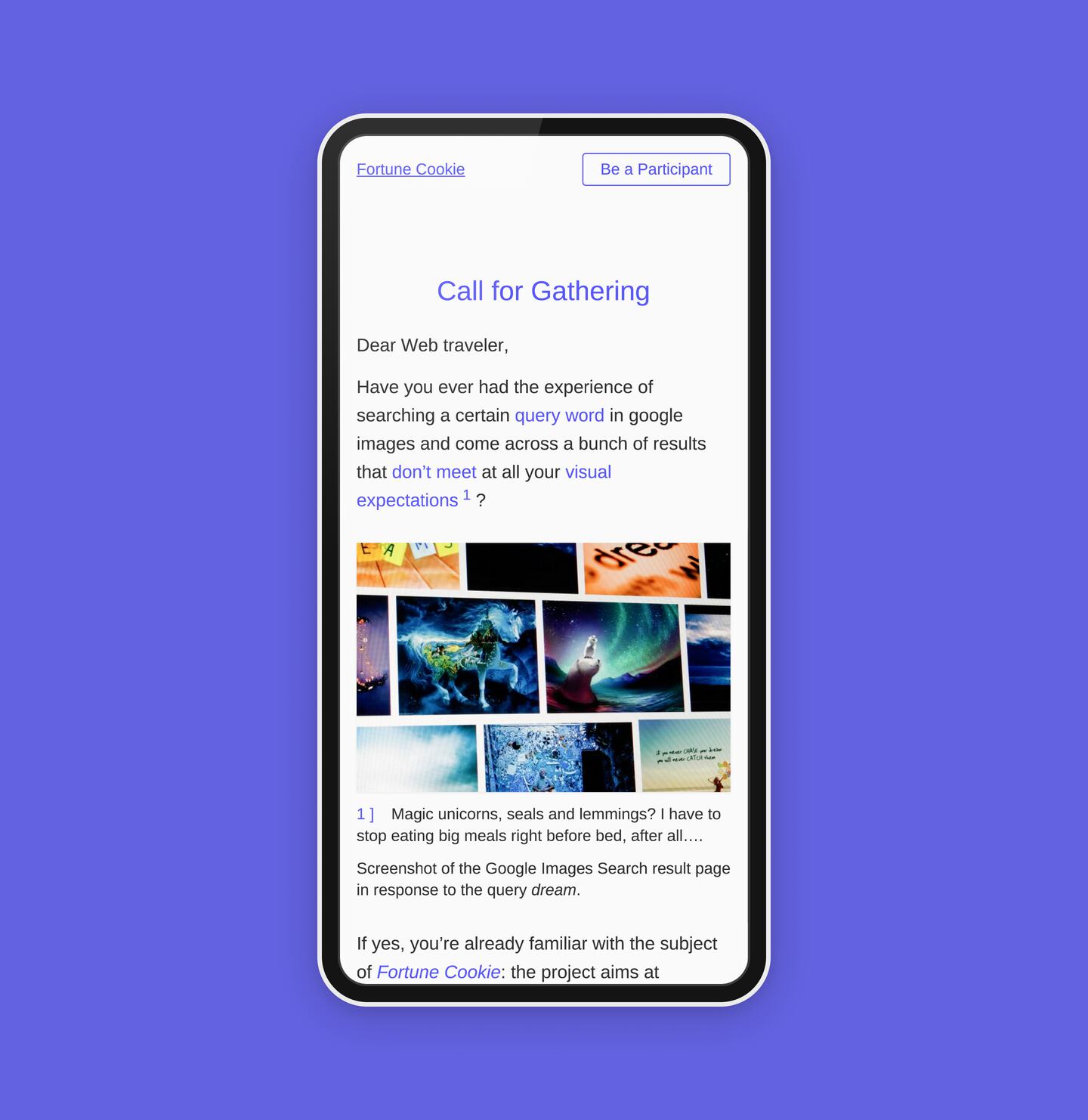
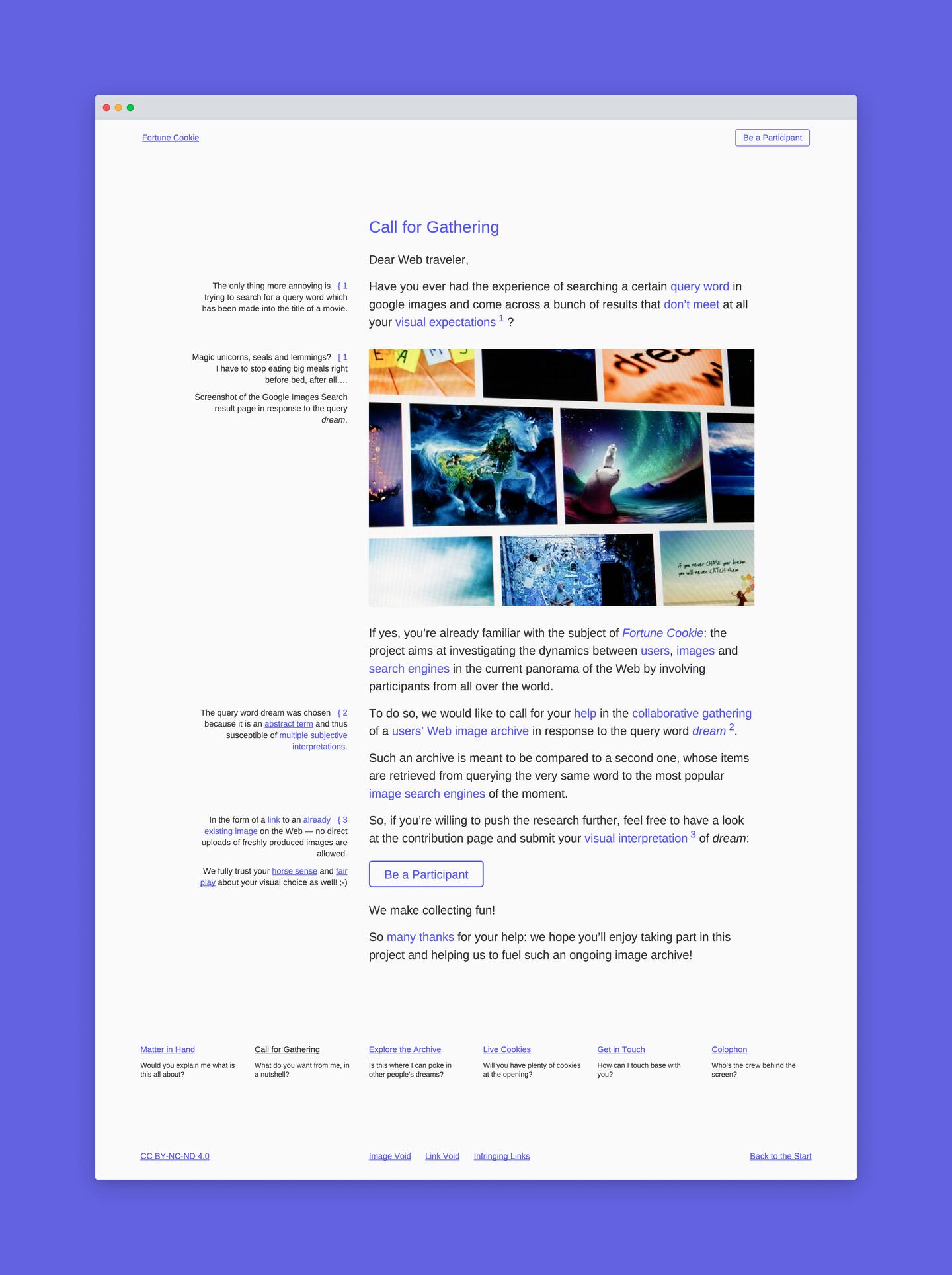
- dream, image search results, responsive, search engines, site
- role
- co-creator, visual/interaction designer
- responsibilities
- concept, information architecture, information + interaction + visual design, back end + front end development
- team
- Andrea Buran, Eleonora Sovrani
The experimental web image archive aims to replicate on a small scale how a human image search engine1 might work.
Unlike a typical image search engine, which returns a set of images based on a user’s query, a human image search engine is powered by multiple users who consciously search for and return visual responses to each other2.
For the sake of simplicity and consistency, the replication is kept at a small scale; all collaborative efforts collected through the site focus on responding to just one predefined query word: dream.
Web travelers are invited to populate the archive by submitting their own visual interpretation in response to the predefined query word or abstract concept dream.
The query word dream was chosen because it is an abstract term, posing a challenge for image search engines. The query word dream was chosen because it is an abstract term, posing a challenge for image search engines. As an abstract term, it is open to multiple subjective interpretations3, and an image search engine cannot know in advance which interpretation the user is truly seeking.
Initially, the interface of the archive was designed to function similarly to that of a typical image search engine. However, a compromise with copyright laws4 on the Internet became necessary, leading to its current form.
Upon learning that even using a thumbnail of a copyrighted image on a web page for documentation purposes—such as what image search engines typically do—could still be considered copyright infringement, it was decided not to use any thumbnails derived from the originals.
As a result, all the thumbnails of the images collected in the archive are generated by scrambling the order of the pixels from their original counterparts.
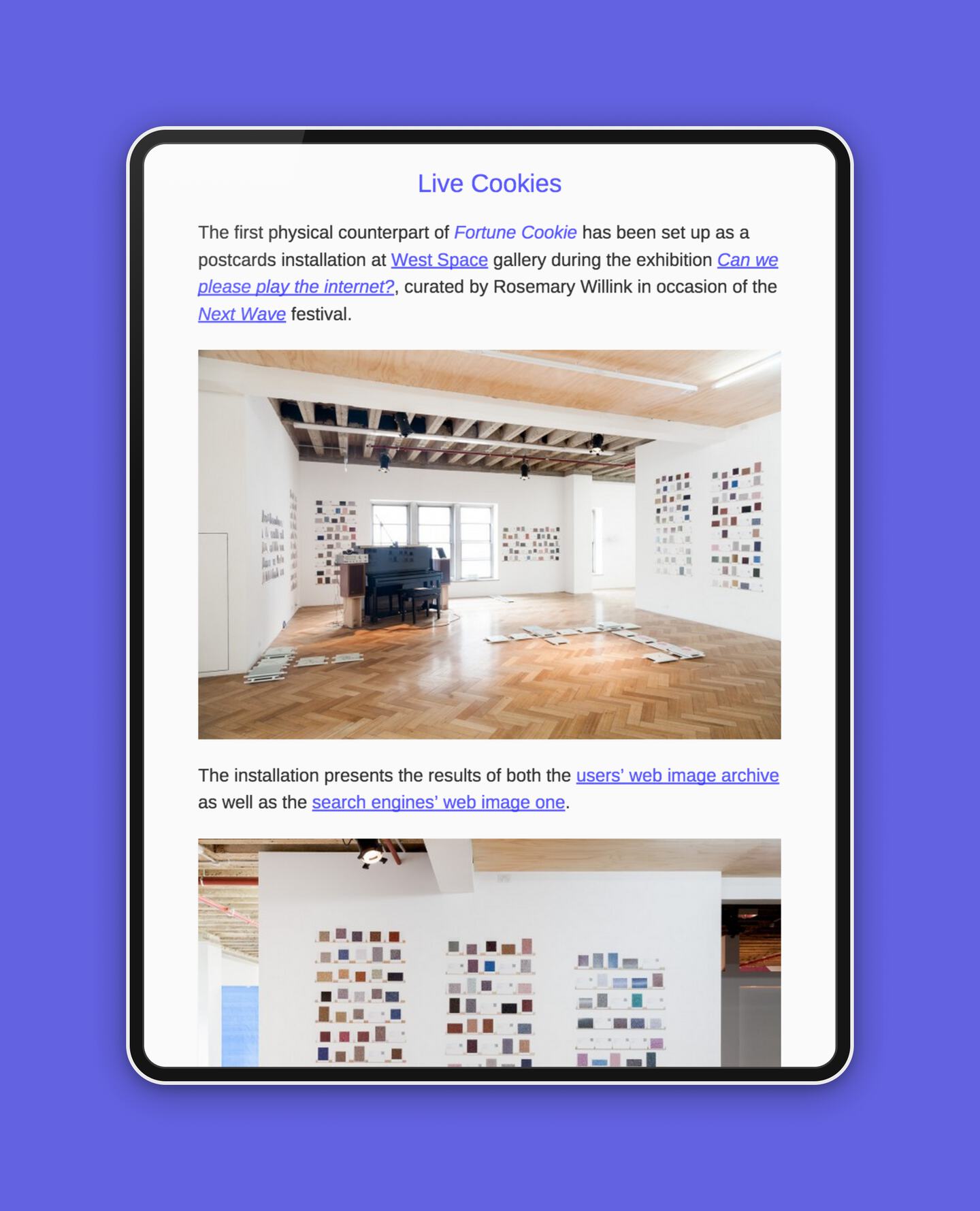
The digital image archive was connected to a physical one in the installation of the same name, set up on occasion of the exhibition Can we please play the internet?.
-
The large-scale collaboration at the basis of a human image search engine would resemble that of a human flesh search engine, but with a focus solely on images. ↩
-
The goal is to subvert the top-down process typical of standard search engines, transforming it into a bottom-up approach. ↩
-
“Image retrieval for abstract concepts is the search for image content that is not directly present in the image, but needs to be inferred from background knowledge and experience.”
— Ron Besseling in Designing an Image Retrieval Interface for Abstract Concepts Within the Domain of Journalism. ↩
-
A jungle of regulations—so watch out for tigers! ↩














